


























NEWS & COLUMN
お知らせ・コラム

SCROLL
MARKETING
ホームページ集客を考える企業に欠かせない!robots.txtの必要性と正しい記述・設置方法
2018
.03.08

GoogleやYahoo!、Bingなどの検索エンジンは、クローラーと呼ばれるロボットがリンクを辿り、様々なページを回遊して情報をインデックスすることで、ユーザーが検索したキーワードと関連性の高いページを検索結果ページに表示させることができます。
自社ホームページを検索結果ページの上位に表示させたいと思う一方で、自社ホームページの中には、検索結果ページに表示させる必要のないページが存在する場合があります。
そのようなページは、Googleなどのクローラーにインデックスしないよう知らせる必要がありますが、どうすれば良いのかわからない…という方も多いのではないでしょうか。
そこで今回は、簡単な記述をするだけでクロールされるのを防ぐことができる「robots.txt」の必要性や正しい記述・設置方法についてお伝えしていきます。
【目次】
1.robots.txtの必要性
2.robots.txtの正しい記述・設置方法
a. User-Agentに対象となるクローラーを記述する
b. Disallowにクロールをブロックするページのディレクトリを記述する
c. Allowにクロールを許可するディレクトリを記述する
3.今回のまとめ
【目次】
robots.txtの必要性
冒頭でもお伝えしたとおり、Googleなどの検索エンジンは、クローラーと呼ばれるロボットがインターネット上をクロールし、ホームページの情報を集め、インデックスしています。そのインデックスした情報を基に、ユーザーに検索されたキーワードと関連性の高いホームページを瞬時に探し出し、検索結果ページに表示しています。
しかし、ホームページの中には、顧客情報を管理しているページやWordPressのプラグインページなど、インターネット上に公開していても検索結果ページには表示させなくても良いページや、ユーザーに見せる必要のないページが存在する場合があります。そのようなページが検索結果ページに表示されているとユーザーは、どのページにアクセスすれば必要としている情報が記載されているのかが分からなくなってしまい、精神的なストレスを感じるだけでなく、ホームページからの離脱率が高まる傾向があります。もしくは、SEO対策において不利な記述や記載内容が含まれているため、クローラーに見せたくないページについても同様です。
そのようなページを検索結果ページに表示させないためにも、Googleなどの検索エンジンに対して、ホームページ内の特定のページをクロールしないようにrobots.txtを記述する必要があります。
robots.txtの正しい記述・設置方法
検索結果ページに表示させる必要のないページなど、ホームページ内の特定のページをクロールしないようGoogleなどのクローラーに知らせるためには、robots.txtに以下の要素を記述する必要があります。
①どのクローラーに対してクロールをブロックするのか
②どのファイルやディレクトリへのクロールをブロックするのか
記述自体は難しいものではないため、続いて解説する記述方法を参考にrobots.txtを記述していきましょう。
User-Agentに対象となるクローラーを記述する
robots.txtでは「User-Agent:」の後に対象となるクローラーの名前を記述します。クローラーの名前は、各クローラーごとに決まっており、Googleだけでもウェブ検索用や画像検索用、そしてAdSense用など複数のクローラーがあります。そのため、特定のクローラーに対する制限を行う場合は、まずクローラーの名前を調べる必要があります。その際は、Googleクローラー Search Console ヘルプを参照ください。
Googleのすべてのクローラーに対して、ホームページ内すべてのファイルへのクロールをブロックする場合は、以下のように記述します。
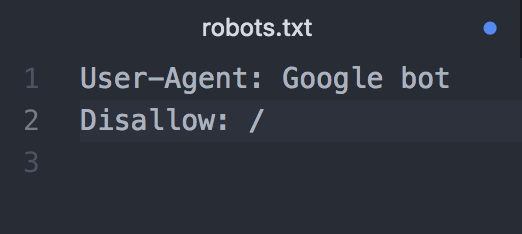
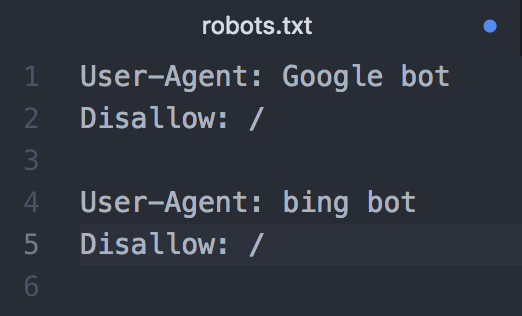
Bingのクローラーに対して、ホームページ内すべてのファイルへのクロールをブロックする場合は、「Google bot」の部分を「bing bot」に変更するだけですが、GoogleとBingなど複数のクローラーを対象にブロックする場合は、以下のように分かりやすいよう間に1行空けてそれぞれの記述を行いましょう。
特定の検索エンジンのクローラーではなく。すべての検索エンジンのクローラーを対象とする場合は、以下のように「*」を記述します。
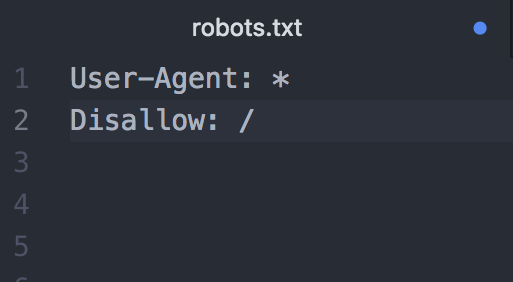
Disallowにクロールをブロックするページのディレクトリを記述する
初期設定では、すべてのページにクロールが許可されていることになっているため、クロールをブロックするページのディレクトリを記述していきましょう。以下のように「Disallow:/」の後にブロックしたいディレクトリ名を記述します。
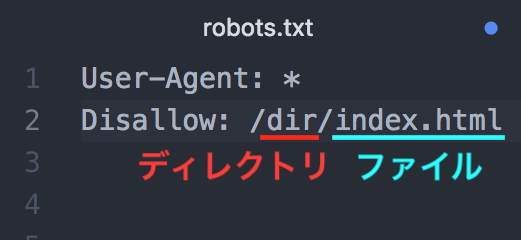
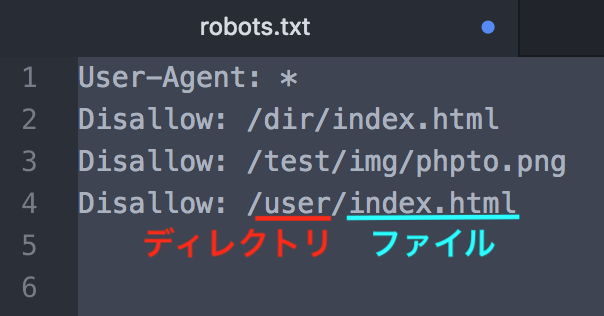
複数のディレクトリをブロックする場合は、「Disallow:/」の行を複数続けて記述します。
Allowにクロールを許可するディレクトリを記述する
「Allow」は、「Disallow」でブロックした中ディレクトリの一部のファイルへのクロールを許可する際に使用します。例えば、「Disallow」を用いて記述したディレクトリとそこに含まれるすべてのファイルをブロックした後、そのディレクトリに含まれる特定のファイルだけクロールを許可したい場合は、以下のように記述します。

この場合は、「dir」ディレクトリに含まれるファイルは全てブロックされますが、「/dir/sample.html」ファイルだけはクロールが許可されます。
以上の記述を行い、作成したrobots.txtファイルは、必ず文字コードを「UTF-8」、名前を「robots.txt」で保存し、「FFFTP」などのFTPツールを利用してホームページのルートディレクトリに設置しましょう。
今回のまとめ
今回は、ホームページ集客を考える上で絶対に欠かすことのできない要素であるrobots.txtの記述・設置方法についてお伝えしました。roots.txtを正しく記述・設置することによって、Googleのクローラーが指定したページをクロールしなくなり、結果的に検索結果ページに表示されなくなります。
ただし、クローラーをブロックしたページに他のページからのリンクが張られていたり、Googleなどの検索エンジンが重要なページだと判断している場合は、robots.txtを正しく設置していても検索結果ページに表示されてしまうことがあります。そのため、自社ホームページにおける各ページの重要性を今一度確認し、ホームページの構成を見直すことも大切です。




ARCHIVE